Page: 1
/
12
Total 59 questions
Curious about Actual Databricks Certified Data Analyst Associate Exam Questions?
Here are sample Databricks Certified Data Analyst Associate (Databricks-Certified-Data-Analyst-Associate) Exam questions from real exam. You can get more Databricks Certified Data Analyst (Databricks-Certified-Data-Analyst-Associate) Exam premium practice questions at TestInsights.
Question 1
A data analyst has a managed table table_name in database database_name. They would now like to remove the table from the database and all of the data files associated with the table. The rest of the tables in the database must continue to exist.
Which of the following commands can the analyst use to complete the task without producing an error?
Start a Discussions
Submit Your Answer:
Question 2
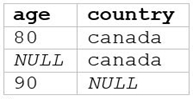
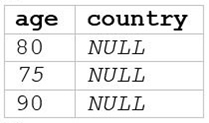
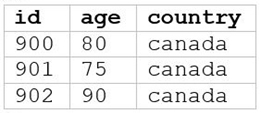
A data analyst runs the following command:
SELECT age, country
FROM my_table
WHERE age >= 75 AND country = 'canada';
Which of the following tables represents the output of the above command?
A)
B)
C)
D)

E)

Start a Discussions
Submit Your Answer:
Question 3
A data analyst runs the following command:
INSERT INTO stakeholders.suppliers TABLE stakeholders.new_suppliers;
What is the result of running this command?
Correct : B
INSERT { OVERWRITE | INTO } [ TABLE ] table_name [ PARTITION clause ] [ ( column_name [, ...] ) | BY NAME ] query
INSERT INTO [ TABLE ] table_name REPLACE WHERE predicate query
The command in the question is missing theOVERWRITEorINTOkeyword, and thequerypart that specifies the source of the data to be inserted. TheTABLEkeyword is optional and can be omitted. ThePARTITIONclause and the column list are also optional and depend on the table schema and the data source. Therefore, the command in the question will fail with a syntax error.
INSERT - Azure Databricks - Databricks SQL | Microsoft Learn
Start a Discussions
Submit Your Answer:
Question 4
A data engineer is working with a nested array column products in table transactions. They want to expand the table so each unique item in products for each row has its own row where the transaction_id column is duplicated as necessary.
They are using the following incomplete command:

Which of the following lines of code can they use to fill in the blank in the above code block so that it successfully completes the task?
Correct : B
I also noticed that you sent me an image along with your message. The image shows a snippet of SQL code that is incomplete. It begins with ''SELECT'' indicating a query to retrieve data. ''transaction_id,'' suggests that transaction_id is one of the columns being selected. There are blanks indicated by underscores where certain parts of the SQL command should be, including what appears to be an alias for a column and part of the FROM clause. The query ends with ''FROM transactions;'' indicating data is being selected from a 'transactions' table.
If you are interested in learning more about Databricks Data Analyst Associate certification, you can check out the following resources:
Start a Discussions
Submit Your Answer:
Question 5
A data analyst is processing a complex aggregation on a table with zero null values and their query returns the following result:
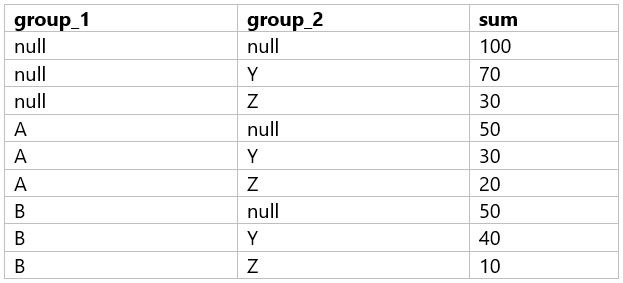
Which of the following queries did the analyst run to obtain the above result?
A)

B)

C)

D)

E)

Correct : B
The result set provided shows a combination of grouping by two columns (group_1 and group_2) with subtotals for each level of grouping and a grand total. This pattern is typical of a GROUP BY ... WITH ROLLUP operation in SQL, which provides subtotal rows and a grand total row in the result set.
Considering the query options:
A) Option A: GROUP BY group_1, group_2 INCLUDING NULL - This is not a standard SQL clause and would not result in subtotals and a grand total.
B) Option B: GROUP BY group_1, group_2 WITH ROLLUP - This would create subtotals for each unique group_1, each combination of group_1 and group_2, and a grand total, which matches the result set provided.
C) Option C: GROUP BY group_1, group 2 - This is a simple GROUP BY and would not include subtotals or a grand total.
D) Option D: GROUP BY group_1, group_2, (group_1, group_2) - This syntax is not standard and would likely result in an error or be interpreted as a simple GROUP BY, not providing the subtotals and grand total.
E) Option E: GROUP BY group_1, group_2 WITH CUBE - The WITH CUBE operation produces subtotals for all combinations of the selected columns and a grand total, which is more than what is shown in the result set.
The correct answer is Option B, which uses WITH ROLLUP to generate the subtotals for each level of grouping as well as a grand total. This matches the result set where we have subtotals for each group_1, each combination of group_1 and group_2, and the grand total where both group_1 and group_2 are NULL.
Start a Discussions
Submit Your Answer: